January 28
So, object based inference, the idea is simple. Current LLM models are text in (called the “prompt”) and text out. Usually set up for user/assistant conversations. However, in coding, you rarely work with language or text, because coding is object based.
I have this proof of concept up and running. For example, I have this OutputObject:
public class MessageOutputObject
{
// Message
public string Message;
// Mood
public Mood Mood;
// Author
public AuthorOutputObject Author = new();
}
// Mood enum
public enum Mood
{
Neutral,
Crazy,
Happy,
Sad,
Angry,
Excited
}
public class AuthorOutputObject
{
// String first name
public string FirstName = "Pet";
// String last name
public string LastName = "L";
}If I call InferObjectAsync, my GBNF generator will automatically generate a grammar:
root::=MessageOutputObject
MessageOutputObject::="{""\"Message\":"Message",""\"Mood\":"Mood",""\"Author\":"Author"}"
string::="\""([^\"]*)"\""
boolean::="true"|"false"
int::=[-]?[0-9]+
uint::=[0-9]+
float::=[-]?[0-9]+"."?[0-9]*([eE][-+]?[0-9]+)?[fF]?
double::=[-]?[0-9]+"."?[0-9]*([eE][-+]?[0-9]+)?[dD]?
Message::=string
Mood::="\"Neutral\""|"\"Crazy\""|"\"Happy\""|"\"Sad\""|"\"Angry\""|"\"Excited\""
Author::=AuthorOutputObject
AuthorOutputObject::="{""\"FirstName\":"FirstName",""\"LastName\":"LastName"}"
FirstName::="\"Pet" ([^\"]*) "\""
LastName::="\"L" ([^\"]*) "\""After that, InferAsync will run as usual, and during every iteration, we will attempt to repair and parse the entire output as JSON, and populate the OutputObject, which looks like this:
[OutputObject]
{
"Message": ". Today was a productive day! I managed to complete several tasks, including writing a new article for the blog and conducting some market research for upcoming projects. The sun was shining, which always helps boost my mood and motivation. Looking forward to another fruitful day tomorrow!",
"Mood": "Happy",
"Author": {
"FirstName": "Peter",
"LastName": "Lee"
}
}So all of this works, we can now let the LLM generate objects, instead of text. But we can’t use this to build a game yet, because there are a couple of issues:
- All rules are appended to a string, which works fine in this case, but breaks during recursion. For example, if we’re writing an array rule, and come across a new object, we’ll start writing the object rule in the middle of the array rule.
- There are no namespaced rules, which will break when conflicting names occur
- There is no way to let the LLM choose between available options. There are enums, but we can’t use those for available actions for example, because we can’t modify enums during runtime.
- Need some way to wrap things in a prompt format (mistral, alpaca)
To tackle the LLM being able to choose from a list of dynamic options, I’m thinking of using an array, and the LLM will simply return an array with a single element (the chosen option). However, sometimes, we might want to the LLM to “complete” an array, so we’ll probably need to use custom attributes. Also, when the LLM chooses “walk to vector3” (for example), how and where do we specify the vector3? This will require the grammar to be updated to include a vector3, but it’s not possible to modify the grammar during inference. Complex issues.
See you soon.
February 2
I have rewritten the grammar generator, and primitive & custom rules + namespacing options and custom attributes are in too. Tomorrow I will tackle the array select mode.
February 3
All done.
Now I’ll get some default executor functionality ready for object and object[] based inference, and start work on the custom executor which uses output from the previous iteration to determine the next. This is what we’ll need to build the game.
While working on this, I came up with something. We can’t modify the grammar during inference (at least, not easily), but we simply might be able to slice the grammar into parts and run inference in parts, which will allow us to modify a future “grammar” that we aren’t processing yet.
February 4
And, done. This is probably the most complex C# code I’ve written because of all the reflection, escaping, custom attributes and what not, but everything seems to be working. In the future, I’ll revisit some of it and simplify/clean things up, but for now this will do.
In the end, I came up with a better way to do the object selection (AssemblyQualifiedName metadata + TypeNameHandling), however, the metadata does cost some tokens in the context. The advantage is that we don’t have to modify the grammar during runtime, we don’t have to do multiple iterations for different objects, the LLM can simply pick an action from a list and it will correctly be casted back to us on the C# side.
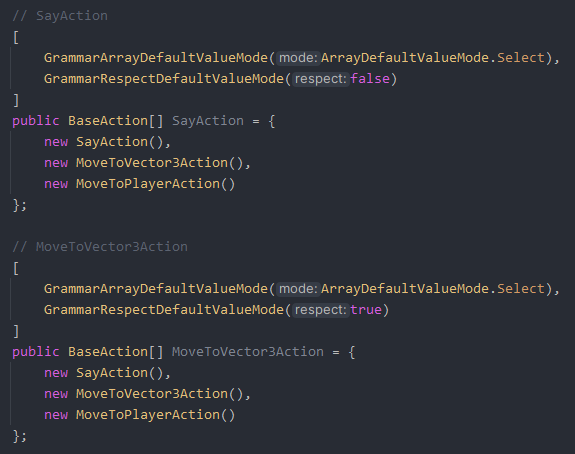
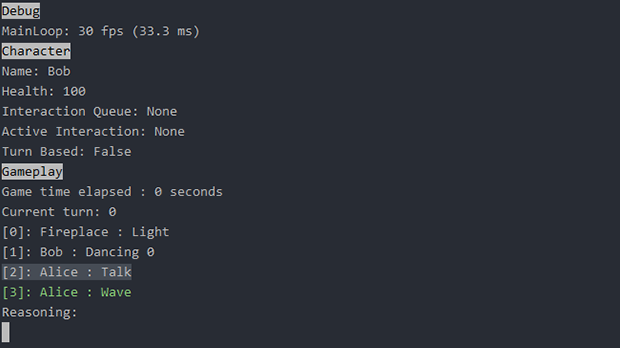
Here I’ve created a new array of the base class (BaseAction) and added a couple of actions (extended from BaseAction) to it. By setting the ArrayDefaultValueMode to Select, we tell the LLM to select a single action from the list and return it to us.
The LLM correctly picks the “SayAction” in the first selector (a correct guess from the LLM based on the variable name!) and picks the MoveToVector3Action in the second selector.
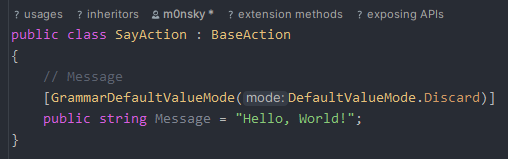
Because the first action does not respect the default value mode overrides, it is ignoring the Discard override mode and making an exact copy (it contains “Hello, World!” by default).
If we had set the GrammarRespectDefaultValueMode to true, it would have respected the Discard override and generated a new sentence for us. Additionally, if the DefaultValueMode of the Message had been set to Complete, it would have completed the sentence.
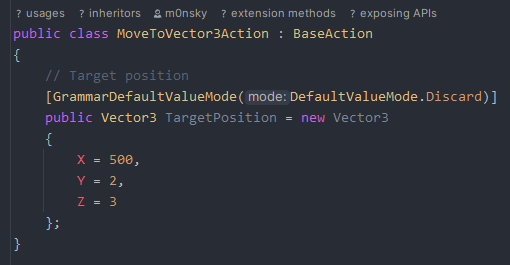
However, for the second action, we do tell it to respect the default value mode override. The “TargetPosition” contains a different Vector3 by default, and it’s correctly discarding it and generating a new Vector3 for us.
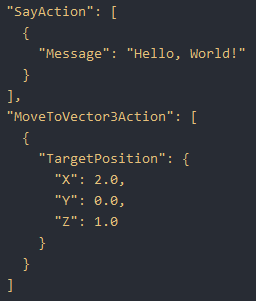
In the end, everything (even though the array is of the type BaseAction) gets correctly casted back their original extended types, and we can properly access the SayAction and MoveToVector3Action objects generated by the LLM.
Edit
Stripping the Version, Culture and PublicKeyToken from the AssemblyQualifiedName saves us some tokens and keeps the parser functionality intact, a nice way to save some tokens.
Edit 2
I’ve added support for training annotations and uuidv4.
- Training annotations are used to explain the training data by giving extra context. They are not rendered in the grammar & inference output, only in the export
- uuidv4 is added to every sample to make every sample unique, even if their contents are identical
These are two tricks I came up with last year that should make the LLM understand the training data better, improve generalization and help avoid overfitting.
I’m not sure if uuidv4 should be disabled in inference, as it could help with generalization in few-shot scenarios, will think about it.
February 7
A couple of things left to do for object based inference:
- Helper functions (in object based executor) for getting context token count, token count per I/O object pair and removing tokens from start to end index
- Input/output object base class (with optional uuid4) and I/O object pairs list (with token count?)
- Keeping track of “dirty” I/O object pairs
- Applying template to dirty object pairs, prepend (serialized) to latest input object before inference
- Applying EOS at the end of the generated grammar. I’ve come across an issue with the default ApplyTemplate behavior, which could be on the C++ side, so we might just hardcode it for now (or at least have it configurable, but not read from the model)
- Custom example that builds on top of the executor to export all object pairs to SFT dataset
- An optionally, a tiny bit of maintenance, better names for GrammarRespectDefaultValueMode and TrainingAnnotation (GrammarIgnoreMember?), some more code commenting, etc
Will hopefully start picking up these tasks tonight. I’ve also started experimenting with a vision encoder which can encode visibility (for example, first person or top down view) into a multidimensional int array, and have checked if my grammar generator code can handle it, and it works! I didn’t intend to make the characters actually “see” or have any spatial awareness, but at least now I know that it’s possible. This could allow characters to actually explore larger, unknown worlds.
February 9
Helper functions, input/output object base class and object pairs are in, but I might get rid of the whole uuid4 idea. Even though it might be able to help with generalization (treating examples as unique, even if their contents look similar), I think it could also cause unwanted behavior due to similar looking uuids (seeing patterns that aren’t there). I will keep it in mind for future experimentation, but won’t try it in this prototype.
Tomorrow I’ll revert some of that complex logic, complete the inference code (“dirty” object pairs, EOS) and try and create an example that can export the object pairs to a SFT dataset.
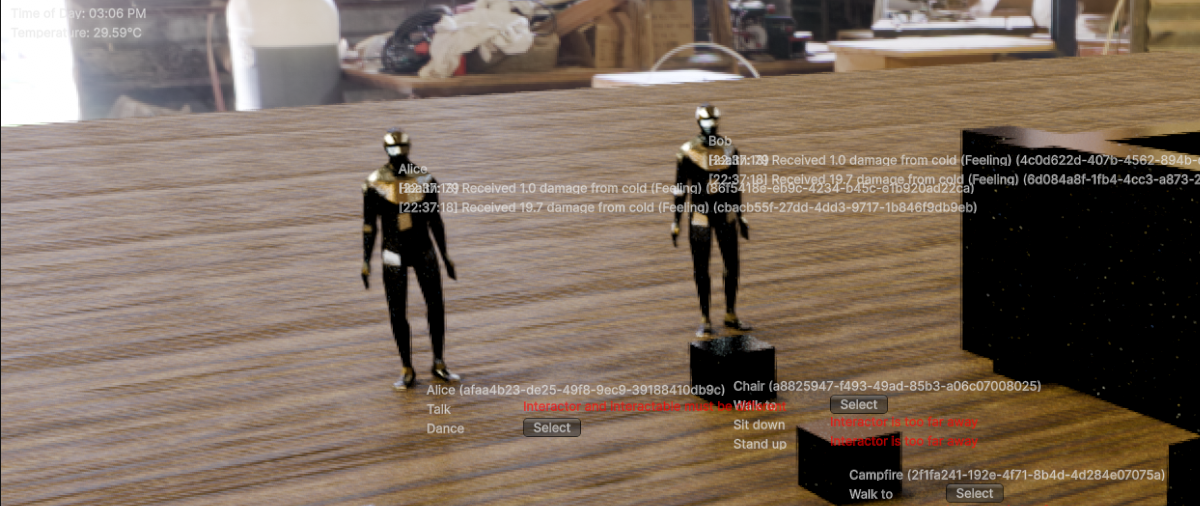
If all goes well, it should be ready for a first test in Unity soon..
Edit
Removed uuid4 code, EOS option is in, started working on object pair inference
February 10
Currently, my ObjectBasedExecutor is built on top of the existing InteractiveExecutor that ships with LLamaSharp. However, to have full control over (correct) prompt template tokenization and managing the context in an object oriented way, it would be better to build a custom executor based on the StatefulExecutorBase instead.
The prototype can definitely be built with the current approach, but it might not work as good as it should, so tonight I’ll decide wether I’ll build a better executor, or not.
For example, this is what the “mistral” template looks like on the LLaMA-Factory (training) side:
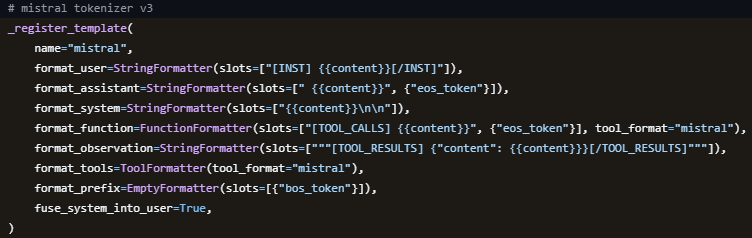
Notice the space between [INST] and {{content}} but not between {{content}} and [/INST]. I’m not sure why their template is set up this way. (a mistake, maybe?)
I’ve been thinking about creating a custom template on the training side, because I don’t like the spaces between the [INST] tags that Mistral uses (obligatory xkcd). It would also make sense because we are not really using instructions (and will not be training on top of an instruct model either!), but input and output objects instead. We could also remove the tool calling template data, since we won’t be using it.
In either case (no matter if we’re using the existing mistral template or not), we need a couple of special tokens. In the case of the default mistral template, the special tokens we need are:
- <s> (BOS)
- </s> (EOS)
According to this page, both [INST] and [/INST] should be inserted as strings, this would explain why a difference in spaces could mess things up!

If we add a space too many, or forget one, we could end up with a difference in tokenization between training and inference.
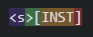
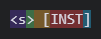
Currently, the ObjectBasedExecutor simply adds the prompt template as raw text and the above are not separated into special tokens. However, we need the actual special tokens, and not as part of the text. (we can’t do it automatically due to prompt injection)

This is where the new executor would come in. We could simply tokenize them as special tokens and use a PreprocessInputs function to apply the prompt template using the special tokens, and leave the prompt template out of any grammar generator related code.
Edit
There’s actually some conflicting information on the [INST] and [/INST] tokens. Mistral’s descriptions on huggingface say they are regular strings, while their official docs say they are special tokens to avoid prompt injection. Will have to dig into this.
Edit 2
After some digging, we do actually need to tokenize [INST] and [/INST] as special, because:
- If we don’t, then there is no way they will correctly tokenize to a single token
- They are listed in the tokenizer configuration (as special!) over here
- It will avoid prompt injection
Edit 3
Special tokens for [INST] and [/INST] were introduced to the vocabulary with the version 0.3 release of the Mistral 7B models, mystery solved!
February 11
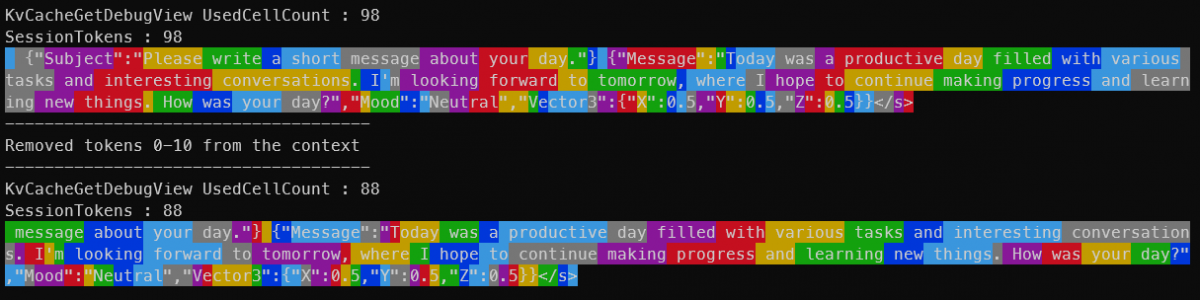
I’ve started working on the custom executor, and a kv cache / context visualization tool.
February 14
The past few days I’ve been preparing, disassembling the existing executors and trying to learn how they work on the lowest level. I think I understand everything clearly now, so this weekend I will:
- Write down my understandings of the flow of the interactive executor
- Write down a proposal for the object based executor, including support for few-shot, handle running out of context and persistent objects (in my imagination, during inference, this looks like a game of tetris)
- Write down ideas for helper functions we need, like removing objects from context (which we’ll re-use for running out of context)
February 20
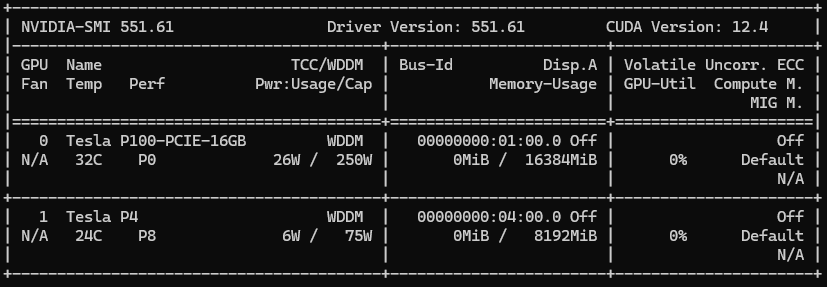
Since the training server with the Tesla P100 is complete, and we’re going to be using that in this part of the blog (after the executor), I’ve started to prepare for the next part of the blog.
I’ve experimented with path tracing + inference on a single GPU last summer, but it required quantizing the model to 2-bit and using a small (2048 tokens) context. I don’t want to get stuck on optimization during prototyping, so I’ve decided to use a dual GPU setup for the prototype.
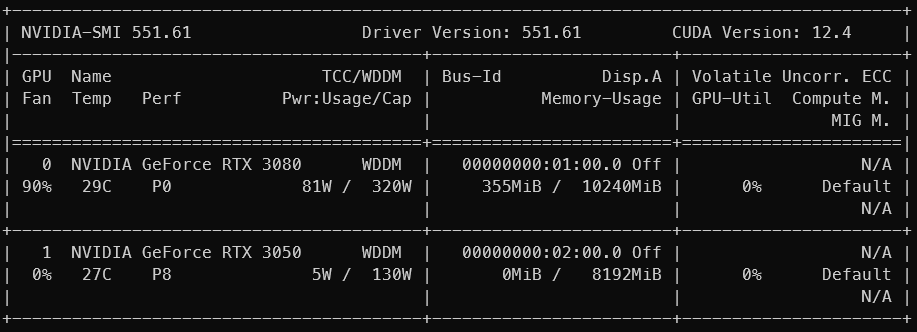
This little RTX 3050 arrived yesterday. It has the same amount of CUDA cores (2560) and VRAM (8 GB) as the Tesla P4, but it has GDDR6 instead of GDDR5, and has tensor cores, which we need.
The RTX 3080 will be used for path tracing, and the RTX 3050 will be used for inference.


February 23
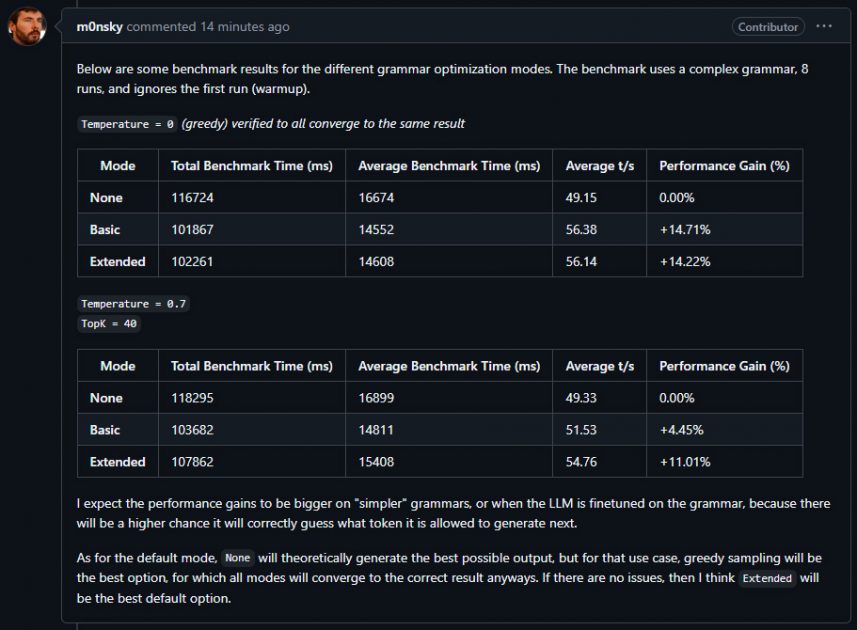
I’ve collaborated with one of the maintainers of LLamaSharp to help introduce grammar optimization modes. Since this game (due to object based inference) will be completely built on grammars, this will bring some big performance increases.
February 25
About halfway through documenting the existing executors, going at a steady pace. I’m analyzing them line by line, writing down the flow in my own words in a notepad so I can turn this into a flowchart later. I’ve come across a bunch of things that can be improved.
Edit
All done.
February 26
Starting work on the object based executor. The idea is to first write down a proposal in my own language and then start coding. More soon.
March 13
Not a lot of updates when it comes to the executor. I think I’ve got everything written down now, so I can start building it in steps.
I’ve verified that the current code is il2cpp compatible which was kind of a concern, and I’ve been solving some rendering math on the side.
March 28
Took a little break.
First of all, the object based executor. I wrote down a proposal in which I tried to cover all possible use cases, and the end result was future proof, but too complicated for the first version. The proposal itself is still useful, since these things need to be thought out in detail anyways.
So, back to the drawing board. What exactly do we need? Let’s apply MoSCoW, a technique I learnt in college.
Must
- Inference for input and output object
- Proper tokenization (with special tokens that match the training data)
- Debug text view of the context/kv cache
- Debug token view of the context/kv cache
- Ability to export all input/output objects to JSON dataset
Should
- Object based out of context handling
- Marking object as persistent
Could
- Inference/decode for input only, in case we want to append information to the kv cache but don’t need a response
- Object softdeletes, which deletes objects from the kv cache, but keeps them in memory for dataset export
- Sharded dataset export. I’m not sure how LLaMa-Factory works with SFT entries that have a history longer than the cutoff_len, I know they do shard PT data. Needs investigating.
Must is simply what has to be done, so let’s focus on that, and put the rest on the backlog.
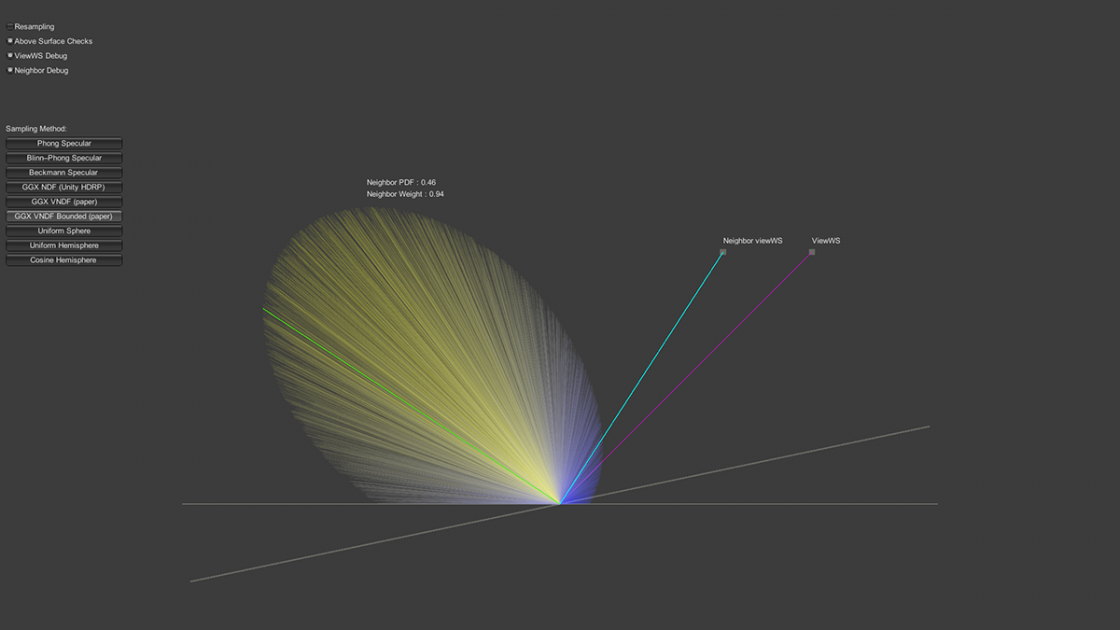
As for the rendering math I’ve been working on, it also has to be done, and I think I can finish it tonight:
- Add specular/diffuse sampling method base classes (base class has viewWS param as Vector3.zero)
- Add cosine hemisphere diffuse
- Add surface base class
- Enable/disable resampler
- Add new weightOverPdf math for HDRP compatibility with bounded VNDF GGX sampling, but I can postpone this until the day I do the actual rendering implementation
March 31
The rendering math is 90% done, I haven’t completed the new weightOverPdf because it’s kind of hard to do this on the C# side (and we don’t even need it there), it’s easier to verify when everything is ported to the HLSL shader side, so it will be done later.
April 28
No post for a while, but there have been updates:
- I upgraded my PSU from 750w to 1000w, so it can properly support dual GPUs
- Finished the object based executor, and also added a stateless version
- I now have a job as an AI/ML Engineer, where I work 4 days a week